
Sinds de huidige rage van door AI gegenereerde dingen zich heeft ontwikkeld, heb ik me afgevraagd: wat zal er gebeuren als de wereld zo vol is van door AI gegenereerde dingen (tekst, software program, afbeeldingen, muziek) dat onze trainingssets voor AI worden gedomineerd door inhoud gemaakt door AI. Op GitHub zien we daar al hints van: in februari 2023 verschijnt GitHub gezegd dat 46% van alle ingecheckte code door Copilot is geschreven. Dat is goed voor het bedrijf, maar wat betekent dat voor toekomstige generaties Copilot? Op een bepaald second in de nabije toekomst zullen nieuwe modellen worden getraind op de code die ze hebben geschreven. Hetzelfde geldt voor elke andere generatieve AI-toepassing: DALL-E 4 zal worden getraind op gegevens die afbeeldingen bevatten die zijn gegenereerd door DALL-E 3, Steady Diffusion, Midjourney en andere; GPT-5 zal worden getraind op een reeks teksten die tekst bevatten die is gegenereerd door GPT-4; enzovoort. Dit is onvermijdelijk. Wat betekent dit voor de kwaliteit van de output die zij genereren? Zal die kwaliteit verbeteren of zal deze eronder lijden?
Ik ben niet de enige die zich dit afvraagt. Ten minste één onderzoeksgroep heeft geëxperimenteerd met het trainen van een generatief mannequin op inhoud die is gegenereerd door generatieve AI, en heeft ontdekt dat de output, gedurende opeenvolgende generaties, strakker beperkt was en minder waarschijnlijk origineel of uniek was. Generatieve AI-output ging in de loop van de tijd steeds meer op zichzelf lijken, met minder variatie. Ze rapporteerden hun resultaten in “De vloek van recursie”, een artikel dat zeker de moeite waard is om te lezen. (Andrew Ng’s nieuwsbrief heeft een uitstekende samenvatting van dit resultaat.)

Leer sneller. Graaf dieper. Zie verder.
Ik heb niet de middelen om grote modellen recursief te trainen, maar ik bedacht een eenvoudig experiment dat analoog zou kunnen zijn. Wat zou er gebeuren als je een lijst met getallen zou nemen, hun gemiddelde en standaarddeviatie zou berekenen, deze zou gebruiken om een nieuwe lijst te genereren, en dat herhaaldelijk zou doen? Dit experiment vereist alleen eenvoudige statistieken – geen AI.
Hoewel er geen gebruik wordt gemaakt van AI, kan dit experiment toch aantonen hoe een mannequin kan instorten als het wordt getraind op de gegevens die het produceert. In veel opzichten is een generatief mannequin een correlatiemotor. Als er een immediate wordt gegeven, genereert het het woord dat het meest waarschijnlijk daarna komt, vervolgens het woord dat het meest daarna komt, enzovoort. Als de woorden ‘To be’ eruit springen, is de kans groot dat het volgende woord ‘of’ is; het volgende woord daarna is zelfs nog waarschijnlijker ‘niet’; enzovoort. De voorspellingen van het mannequin zijn min of meer correlaties: welk woord is het sterkst gecorreleerd met wat eraan voorafging? Als we een nieuwe AI trainen op zijn output en het proces herhalen, wat is dan het resultaat? Krijgen we uiteindelijk meer variatie, of minder?
Om deze vragen te beantwoorden, heb ik een Python-programma geschreven dat een lange lijst met willekeurige getallen (1000 elementen) genereerde volgens de Gaussiaanse verdeling met gemiddelde 0 en standaardafwijking 1. Ik nam het gemiddelde en de standaardafwijking van die lijst en gebruikte deze om genereer nog een lijst met willekeurige getallen. Ik herhaalde dit 1000 keer en noteerde vervolgens het uiteindelijke gemiddelde en de standaarddeviatie. Dit resultaat was suggestief: de standaarddeviatie van de uiteindelijke vector was bijna altijd veel kleiner dan de initiële waarde van 1. Maar deze varieerde sterk, dus besloot ik het experiment (1000 iteraties) 1000 keer uit te voeren en de uiteindelijke standaarddeviatie te middelen van elk experiment. (1000 experimenten is overdreven; 100 of zelfs 10 zullen vergelijkbare resultaten opleveren.)
Toen ik dit deed, werd de standaarddeviatie van de lijst vergroot (ik zal niet zeggen “geconvergeerd”) tot ongeveer 0,45; hoewel het nog steeds varieerde, lag het bijna altijd tussen 0,4 en 0,5. (Ik heb ook de standaarddeviatie van de standaarddeviaties berekend, hoewel dit niet zo interessant of suggestief was.) Dit resultaat was opmerkelijk; mijn intuïtie vertelde me dat de standaarddeviatie niet zou instorten. Ik verwachtte dat deze dicht bij 1 zou blijven, en het experiment zou geen ander doel dienen dan het uitoefenen van de ventilator van mijn laptop computer. Maar met dit eerste resultaat in de hand kon ik het niet laten om verder te gaan. Ik heb het aantal iteraties steeds opnieuw verhoogd. Naarmate het aantal iteraties toenam, werd de standaardafwijking van de uiteindelijke lijst steeds kleiner en daalde tot .0004 bij 10.000 iteraties.
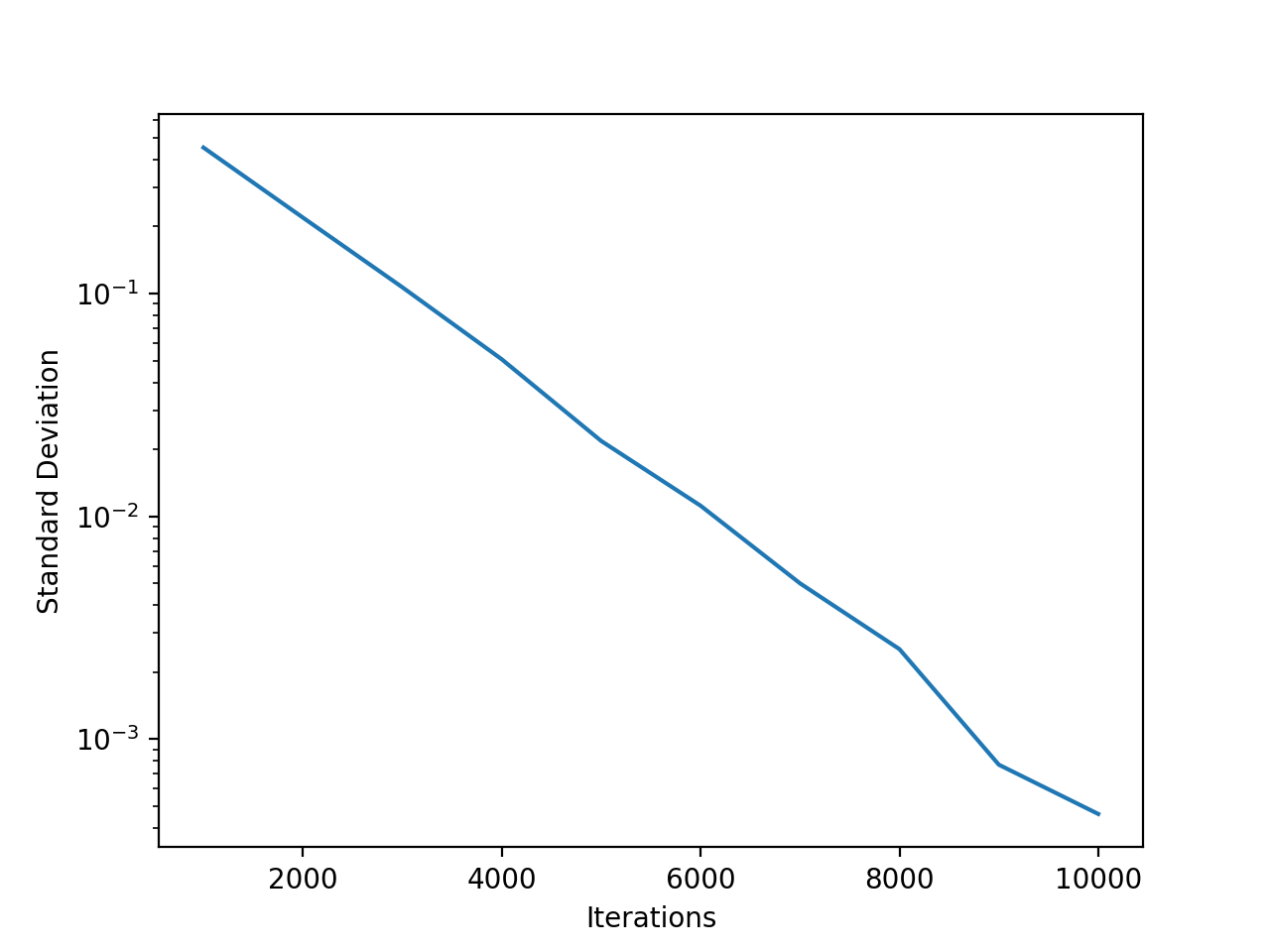
Ik denk dat ik weet waarom. (Het is zeer waarschijnlijk dat een echte statisticus naar dit probleem zou kijken en zeggen: “Het is een voor de hand liggend gevolg van de moist van de grote aantallen.”) Als je de standaarddeviaties stap voor stap bekijkt, is er veel variatie. We genereren de eerste lijst met een standaardafwijking van één, maar als we de standaardafwijking van die gegevens berekenen, krijgen we waarschijnlijk een standaardafwijking van 1,1 of 0,9 of bijna iets anders. Wanneer je het proces vele malen herhaalt, domineren de standaarddeviaties kleiner dan één, ook al zijn ze niet waarschijnlijker. Ze verkleinen de ‘staart’ van de distributie. Wanneer u een lijst met getallen genereert met een standaardafwijking van 0,9, is de kans veel kleiner dat u een lijst krijgt met een standaardafwijking van 1,1, maar eerder een standaardafwijking van 0,8. Zodra de staart van de verdeling begint te verdwijnen, is het zeer onwaarschijnlijk dat deze weer zal groeien.
Wat betekent dit eventueel?
Mijn experiment laat zien dat als je de output van een willekeurig proces terugvoert naar de enter, de standaarddeviatie instort. Dit is precies wat de auteurs van ‘The Curse of Recursion’ beschreven toen ze rechtstreeks met generatieve AI werkten: ‘de staarten van de distributie verdwenen’, bijna volledig. Mijn experiment biedt een vereenvoudigde manier om over ineenstorting na te denken, en laat zien dat het ineenstorten van modellen iets is dat we mogen verwachten.
De ineenstorting van het mannequin stelt de ontwikkeling van AI voor een ernstig probleem. Oppervlakkig gezien is het voorkomen ervan eenvoudig: sluit gewoon door AI gegenereerde gegevens uit van trainingssets. Maar dat is niet mogelijk, althans nu niet omdat er instruments zijn voor het detecteren van door AI gegenereerde inhoud bewezen onjuist. Watermerken kunnen helpen, hoewel watermerken ook voordelen opleveren eigen reeks problemen, inclusief de vraag of ontwikkelaars van generatieve AI deze zullen implementeren. Hoe moeilijk het elimineren van door AI gegenereerde inhoud ook is, het verzamelen van door mensen gegenereerde inhoud kan een even groot probleem worden. Als door AI gegenereerde inhoud de door mensen gegenereerde inhoud verdringt, kan door mensen gegenereerde inhoud van hoge kwaliteit moeilijk te vinden zijn.
Als dat zo is, kan de toekomst van generatieve AI somber zijn. Naarmate de trainingsgegevens steeds meer worden gedomineerd door door AI gegenereerde output, zal het vermogen om te verrassen en te verrassen afnemen. Het zal voorspelbaar, saai en saai worden en waarschijnlijk niet minder snel ‘hallucineren’ dan nu het geval is. Om onvoorspelbaar, interessant en creatief te zijn, hebben we onszelf nog steeds nodig.