
AMD tilde de motorkap op van zijn volgende AI-acceleratorchip, de Intuition MI300, op de AMD Geavanceerde AI evenement van vandaag, en het is een ongekende prestatie 3D-integratie. MI300, waarvan een versie de de kapitein supercomputer, is een gelaagde taart van computer systems, geheugen en communicatie die drie plakjes siliciumhoog is en maar liefst 17 terabytes aan gegevens verticaal tussen die plakjes kan slingeren. Het resultaat is een snelheidsverhoging van maar liefst 3,4 maal voor bepaalde machine learning-kritieke berekeningen. De chip biedt zowel contrasten als overeenkomsten met concurrerende benaderingen zoals die van Nvidia Grace-Hopper-superchip en Intel’s supercomputerversneller Ponte Vecchio.
MI300a stapelt drie CPU’s chipjes (in AMD’s jargon compute advanced dies of CCD’s genoemd) en zes accelerator-chiplets (XCD’s) bovenop vier input-output dies (IOD’s), allemaal bovenop een stuk silicium dat ze met elkaar verbindt tot acht stapels hoogwaardige bandbreedte DRAM die de superchip laat overgaan. (De MI300x vervangt de CCD’s door nog twee XCD’s, voor een systeem met alleen een versneller.) Nu de schaling van transistors in het vlak van het silicium langzamer gaat, wordt 3D-stapeling gezien als een sleutelmethode om meer transistors in hetzelfde gebied te krijgen en blijf de moist van Moore voortdrijven.
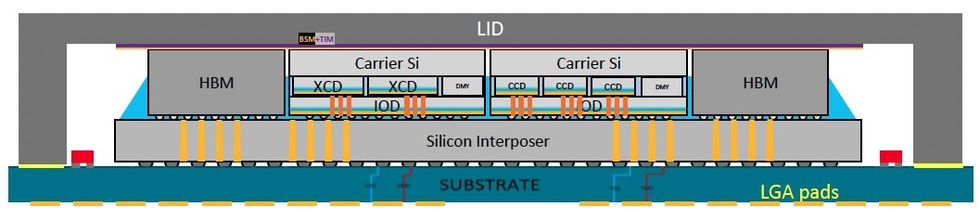 Compute- en AI-chiplets zijn gestapeld bovenop I/O- en cache-chiplets in de MI300a.AMD
Compute- en AI-chiplets zijn gestapeld bovenop I/O- en cache-chiplets in de MI300a.AMD
“Het is een werkelijk verbazingwekkende siliciumstapeling die de hoogste dichtheidsprestaties levert die de industrie op dit second weet te produceren”, zegt Sam Naffziger, een senior vice-president en company fellow bij AMD. De integratie gebeurt met behulp van twee TSMC-technologieën, SoIC (systeem op geïntegreerde chips) en CoWoS (chip op wafer op substraat). Deze laatste stapelt kleinere chips op grotere chips met behulp van zogenaamde hybride binding, waarbij koperen pads op elke chip direct met elkaar worden verbonden zonder soldeer. Het wordt gebruikt om AMD’s te produceren V-cache, een cachegeheugen-uitbreidende chiplet die wordt gestapeld op de hoogste CPU-chiplets. De eerste, CoWos, stapelt chiplets op een groter stuk silicium, een zogenaamde interposer, dat is gebouwd om verbindingen met hoge dichtheid te bevatten.
Overeenkomsten en verschillen tussen AMD en Nvidia
Er zijn zowel overeenkomsten als verschillen met de aanpak van belangrijkste concurrent Nvidia. Web zoals Nvidia deed met zijn Hopper-architectuur, voegde AMD’s acceleratorarchitectuur, CDNA3, de mogelijkheid toe om te computeren met afgeknotte 32-bits getallen genaamd TF32 en met twee verschillende vormen van 8-bit drijvende-kommagetallen. Dit laatste kenmerk wordt gebruikt om de coaching van bepaalde delen van neurale netwerken van transformatoren, zoals grote taalmodellen, te versnellen. Ze bevatten ook allebei een een schema dat de omvang van het neurale netwerk verkleintgenaamd 4:2-sparsiteit.
Een andere overeenkomst is de opname van zowel CPU als GPU in hetzelfde pakket. In veel AI-computersystemen zijn GPU’s en CPU’s afzonderlijk verpakte chips die in een verhouding van 4 op 1 worden ingezet. Een voordeel van het samenvoegen ervan in één enkele superchip is dat zowel de CPU als de GPU toegang hebben met hoge bandbreedte tot dezelfde cache en DRAM (HBM) met hoge bandbreedte, op een manier die elkaar niet in de struggle brengt tijdens het lezen en schrijven van gegevens. .
Nvidia’s Grace-Hopper is zo’n superchipcombinatie die de Grace CPU met de Hopper GPU verbindt by way of Nvidia’s Nvidia NVLink Chip-2-Chip-interconnects. AMD’s MI300a is dat ook, door drie CPU-chips te integreren die zijn ontworpen voor de Genoa-lijn en zes XCD-accelerators die gebruik maken van de AMD Infinity Material-verbindingstechnologie.
Maar een oppervlakkige blik op Grace Hopper en MI300 laat enkele diepgaande verschillen zien. Grace en Hopper zijn stuk voor stuk individuele dies die alle benodigde functionele blokken van een systeem op de chip integreren: rekenkracht, I/O en cache. Ze zijn horizontaal met elkaar verbonden en ze zijn groot, bijna op de grens van de fotolithografische technologie.
AMD koos voor een andere aanpak, een aanpak die het al verschillende generaties van zijn CPU’s en rivaal volgt Intel gebruikt voor zijn 3D-gestapelde supercomputerversneller Ponte Vecchio. Het idea heet systeem-technologie-co-optimalisatie, of STCO. Dat betekent dat ontwerpers begonnen met het opsplitsen van de chip in zijn functies en besloten welke functies welke productietechnologie nodig hadden.
 Een stukje MI300-stapel van het dragersilicium aan de bovenkant tot de soldeerbal aan de onderkant van de verpakking.AMD
Een stukje MI300-stapel van het dragersilicium aan de bovenkant tot de soldeerbal aan de onderkant van de verpakking.AMD
“Wat we met MI300 wilden doen, was verder schalen dan mogelijk was met een enkele monolithische GPU. Dus hebben we het in stukken gedeconstrueerd en vervolgens weer opgebouwd”, zegt Alan Smit, een senior fellow en de hoofdarchitect van Intuition. Hoewel dit al verschillende generaties CPU’s wordt gedaan, is de MI300 de eerste keer dat het bedrijf GPU-chiplets maakt en deze in één systeem samenvoegt.
“Door de GPU in chiplets op te delen, konden we de rekenkracht in het meest geavanceerde procesknooppunt plaatsen, terwijl de relaxation van de chip in technologie bleef die geschikter is voor cache en I/O”, zegt hij. In het geval van de MI300 werd alle rekenkracht gebouwd met behulp van het N5-proces van TSMC, het meest geavanceerde proces dat beschikbaar is en dat wordt gebruikt voor de toplijn-GPU’s van Nvidia. Noch de I/O-functies, noch het cachegeheugen van het systeem profiteren van N5, dus koos AMD daarvoor voor een goedkopere technologie (N6). Daarom zouden deze twee functies dan samen op dezelfde chiplet kunnen worden gebouwd.
Nu de functies zijn verbroken, zijn alle stukjes silicium die bij de MI300 betrokken zijn, klein. De grootste, de I/O-dies, zijn nog niet eens half zo groot als Hopper. En de CCD’s zijn slechts ongeveer 1/5e grootte van de I/O-chip. De kleine maten maken een groot verschil. Over het algemeen leveren kleinere chips een betere opbrengst op. Dat wil zeggen, een enkele wafel zal een groter aandeel werkende kleine chips verschaffen dan grote chips. “3D-integratie is niet free of charge”, zegt Naffziger. Maar de hogere opbrengst compenseert de kosten, zegt hij.
Geluk en ervaring
Het ontwerp omvatte een slim hergebruik van bestaande technologieën en ontwerpen, een paar compromissen en een beetje geluk, aldus Naffziger, een IEEE Fellow. Het hergebruik kwam in twee gevallen voor. Ten eerste was AMD in staat om de 3D-integratie met een zekere mate van vertrouwen uit te voeren, omdat het al precise dezelfde afstand van verticale verbindingen (9 micrometer) had gebruikt in zijn V-cache-product.
Als optionele add-on waar AMD additional voor in rekening kon brengen, had V-cache weinig risico dat een slechte opbrengst of andere problemen een grote influence zouden hebben op het bedrijf. “Het was geweldig om ons in staat te stellen de productieproblemen en alle ontwerpcomplexiteiten van 3D-stapelen op te lossen zonder de hoofdproductlijn in gevaar te brengen”, zegt Naffziger.
Het andere voorbeeld van hergebruik was een beetje kansrijker. Toen het MI300-team besloot dat een CPU/GPU-combinatie nodig was, vroeg Naffziger “enigszins schaapachtig” aan het hoofd van het group dat de Zen4 CCD ontwierp voor de Genua CPU, als de CCD gemaakt zou kunnen worden om aan de behoeften van de MI300 te voldoen. Dat group stond onder druk om een eerdere deadline te halen dan verwacht, maar een dag later reageerden ze. Naffziger had geluk; de Zen4 CCD had precies op de juiste plek een kleine lege ruimte om de verticale verbindingen met de MI300 I/O-chip en de bijbehorende circuits te maken zonder het algehele ontwerp te verstoren.
Niettemin was er nog steeds een geometrie die moest worden opgelost. Om alle interne communicatie te laten werken, moesten de vier I/O-chiplets op een bepaalde rand naar elkaar toe gericht zijn. Dat betekende dat er een spiegelbeeldversie van de chiplet moest worden gemaakt. Omdat hij samen met de I/O-chiplet werd ontworpen, werden de verticale aansluitingen van de XCD gebouwd om verbinding te maken met beide versies van de I/O. Maar er was geen gedoe met de CCD, en ze hadden het geluk dat ze die al hadden. In plaats daarvan werd de I/O ontworpen met redundante verbindingen, zodat de CCD verbinding zou maken, ongeacht op welke versie van de chiplet deze zat.
 Om alles op één lijn te krijgen moesten de IOD-chiplets als spiegels van elkaar worden gemaakt en moesten de accelerator- (XCD) en compute-chiplets (CCD) worden geroteerd.AMD
Om alles op één lijn te krijgen moesten de IOD-chiplets als spiegels van elkaar worden gemaakt en moesten de accelerator- (XCD) en compute-chiplets (CCD) worden geroteerd.AMD
Het elektriciteitsnet, dat honderden ampère stroom moet leveren aan de computerchips bovenaan de stapel, stond voor soortgelijke uitdagingen, omdat het ook alle verschillende chipletoriëntaties moest accommoderen, merkte Naffziger op.
Van uw siteartikelen
Gerelateerde artikelen op web